Die Berechnung der Verkehrsströme im Wirtschaftsverkehr erfolgt in zwei aufeinander aufbauenden Rechenverfahren. Im ersten Schritt wird mit dem Verfahren Wirtschaftsverkehr Erzeugung und Verteilung das Aufkommen und die räumliche Verteilung der Aufträge ermittelt. In einem zweiten Schritt werden aus den Aufträgen im Verfahren Wirtschaftsverkehr Fahrtengenerierung die eigentlichen Fahrtenmatrizen errechnet.
Erzeugung und Verteilung
Das Verfahren Wirtschaftsverkehr Erzeugung und Verteilung bündelt die beiden Schritte der Erzeugung und der räumlichen Verteilung der Aufträge. Die Vorgehensweise ist dabei eng an das Vier-Stufen-Modell (Standard-Vier-Stufen-Modell in zwei Varianten) angelehnt, weist aber einige Besonderheiten auf.
Erzeugung
Das Quellaufkommen einer Nachfrageschicht in einem Bezirk hängt von strukturellen Kenngrößen des Bezirks ab, die die Intensität der Wirtschaftstätigkeit beschreiben. Übliche Kenngrößen sind hier die Zahl der Arbeitsplätze, die Betriebsflächen, Anzahl Kfz oder ähnlich. Diese Kenngrößen sind zumeist aus statistischen Daten und Landnutzungsinformationen ableitbar. Sie werden üblicherweise nach Quellbranchen aufgeschlüsselt benötigt. Weiterhin werden – als Verhaltensparameter – Erzeugungsraten benötigt, die angeben, wie viele Aufträge je Einheit der strukturellen Kenngröße generiert werden. In allgemeiner Form wird die Erzeugung über die Formel
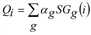
ermittelt.
Im Verfahren wird das Quellaufkommen je Nachfrageschicht analog zum Vier-Stufen-Modell über eine durch Formeln frei definierbare Quellaufkommensdefinition ermittelt. Somit können die Kenngrößen flexibel aus anderen Größen abgeleitet und Erzeugungsraten im Datenmodell vorgehalten werden. Die ermittelten Quellaufkommen liegen implizit in der Einheit Aufträge vor (diese wird nicht explizit im Datenmodell verwendet) und werden im Attribut Quellaufkommen(NSch) an den Bezirken gespeichert.
Für die Ermittlung des Zielaufkommens stehen zwei alternative Berechnungswege zur Verfügung. Zum einen kann auch hier – wiederum analog zum Vier-Stufen-Modell – das Zielaufkommen direkt über eine Formel definiert werden. Falls sich die Quell- und Zielaufkommen nicht bereits aufgrund der verwendeten Attribute und Erzeugungsraten ausgleichen, können Sie über einen Verfahrensparameter einstellen, ob die Quell- und Zielaufkommen so skaliert werden sollen, dass ihre Summen gleich sind. Als Bezugswert können Sie das Gesamtquellaufkommen, das Gesamtzielaufkommen oder Minimum, Maximum oder Mittelwert beider Größen vorgeben.
In vielen Fällen ist schwierig, die benötigten Daten und Koeffizienten zur direkten Berechnung von Zielaufkommen zu ermitteln, da aus Befragungen und Statistiken in der Regel keine Daten auf Ebene der Zielbranchen, sondern eher für die Quellbranchen vorliegen. Daher können die Zielaufkommen alternativ auch aus den Quellaufkommen abgeleitet werden. Dazu sind zusätzlich Informationen zu den wirtschaftlichen Verflechtungen erforderlich, d.h. Angaben dazu, wie sich das gesamte Auftragsvolumen einer Quellbranche auf die verschiedenen Empfängerbranchen verteilt. Solche Daten können in Unternehmensbefragungen erhoben werden. Falls solche Befragungen nicht vorliegen, kann gegebenenfalls auch auf öffentliche Statistiken wie die Input/Output-Rechnung zurückgegriffen werden. Weiterhin muss das Empfangspotential der Empfängerbranchen in den Bezirken wiederum über Kenngrößen beschrieben werden. Die Berechnung des Zielaufkommens erfolgt dann nach der folgenden Formel:
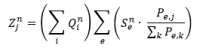
wobei
|
|
Quellaufkommen am Quellbezirk i für Nachfrageschicht n |
|
|
Zielaufkommen an Zielbezirk j für Nachfrageschicht n |
|
|
Anteil der Empfängerbranche e am gesamten Quellaufkommen in Nachfrageschicht n |
|
|
Empfangspotential der Empfängerbranche e für Zielbezirk j |
|
n |
Nachfrageschicht |
|
e |
Empfängerbranche |
| i, j, k |
Bezirksindizes |




In den Verfahrensparametern wird dazu für jede Nachfrageschicht angegeben, welche Anteile des gesamten Quellaufkommens auf die verschiedenen Empfängerbranchen entfallen und wie die jeweiligen Empfangspotentiale der Bezirke in den Empfängerbranchen bestimmt werden. Dabei werden auch Branchen berücksichtigt, die lediglich als Zielbranchen definiert sind und die somit nicht direkt einer Nachfrageschicht zugeordnet sind, z.B. die privaten Haushalte, die lediglich als Empfänger von Leistungen fungieren. Die so ermittelten Zielaufkommen je Nachfrageschicht und Empfängerbranche werden auf Nachfrageschichten aggregiert.
Bei beiden Berechnungsformen werden mögliche externe Verflechtungen ignoriert, d.h. es wird implizit davon ausgegangen, dass das gesamte Quellaufkommen an Aufträgen auf das Untersuchungsgebiet entfällt, und die Empfängerbranchen dort auch nur aus dem Untersuchungsgebiet heraus bedient werden. Die Ergebnisse werden in beiden Fällen je Nachfrageschicht im Attribut Zielaufkommen(NSch) an den Bezirken gespeichert.
Sie können die gesamte Berechnung auf die aktiven Bezirke einschränken. Dies bietet sich beispielsweise an, wenn das Netzmodell sowohl den eigentlichen Planungsraum als auch umgebende Kordonbezirke umfasst. Wenn Sie nur den Binnenverkehr des Planungsraums mit dem Nachfragemodell berechnen wollen, so definieren Sie vorab einen Filter nur für die im Planungsraum liegenden Bezirke. Ähnlich gehen Sie vor, wenn die Erzeugungsraten nicht einheitlich für alle Bezirke sind. Unterteilen Sie die Bezirke in Gruppen mit homogenen Erzeugungsraten und fügen Sie für jede dieser Gruppen ein Verfahren Verkehrserzeugung in den Verfahrensablauf ein. Laden Sie vor jedem Verfahren dieser Art einen Filter für die Bezirke der Gruppe (Verfahren Filter lesen (Filter während des Verfahrensablaufs lesen)) und berechnen Sie die Verkehrserzeugung jeweils nur für die aktiven Bezirke.
Wenn das Verfahren in einem iterativen Nachfragemodell mit Rücksprung eingesetzt wird (Iterative Wiederholung), ist es gegebenenfalls nicht sinnvoll, die Erzeugung in jeder Iteration erneut zu berechnen. Eine Option in den Verfahrensparametern erlaubt es daher, die Berechnung der Erzeugung nur in der ersten Iteration durchzuführen.
Verteilung
Die Verteilung entspricht vollständig der Verkehrsverteilung aus dem Vier-Stufen-Modell (Verkehrsverteilung). Anstatt in Personenfahrten wird in der virtuellen Einheit Aufträge gerechnet, die jedoch nicht explizit auftritt. Ergebnis des Verfahrens ist also eine Verteilungsmatrix der Aufträge je Nachfrageschicht.
Fahrtengenerierung
Das Verfahren Fahrtengenerierung hat den Zweck, aus den Verteilungsmatrizen der Aufträge Fahrtenmatrizen zu erstellen. Wie bereits dargestellt, werden im Wirtschaftsverkehr vielfach mehrere Aufträge innerhalb einer Tour eines Fahrzeugs bedient. Der Grad der Tourbildung und die räumliche Charakteristik der Touren variieren dabei je nach Branche und Logistikkonzept. Mit dem Verfahren Fahrtengenerierung werden die Touren nicht explizit als zusammenhängende Fahrtketten auf der (mikroskopischen) Ebene von Einzelfahrzeugen abgebildet. Stattdessen arbeitet das Verfahren makroskopisch und bildet die einzelnen Toursegmente als Fahrten zwischen Bezirken ab, die für alle Fahrzeuge gemeinsam in Matrizen gespeichert werden. Aus einer (gedachten) Tour eines zu einem bestimmten Logistikkonzept einer Branche zählenden Fahrzeugs werden dabei unterschiedliche Arten von Fahrten erzeugt:
- Eine Startfahrt vom Heimatbezirk zum ersten Auftragsort (Bezirk)
- Gegebenenfalls mehrere Verbindungsfahrten zwischen den weiteren Auftragsorten
- Eine Rückfahrt vom letzten Auftragsort zum Heimatbezirk
Zur Ermittlung und räumlichen Zuordnung der unterschiedlichen Fahrtarten wird wie folgt vorgegangen:
1. Ermittlung der Startfahrten je Quellbezirk
2. Räumliche Verteilung der Startfahrten
3. Ermittlung der Restaufträge und der erforderlichen Verbindungsfahrten
4. Räumliche Verteilung der Verbindungsfahrten
5. Bestimmung der Rückfahrten
6. Ausgabe der Fahrtenmatrizen
Ermittlung der Startfahrten je Quellbezirk
Da das Verfahren makroskopisch arbeitet, findet keine Optimierung der Auftragszuordnung (Traveling Salesman) statt, sondern es wird davon ausgegangen, dass alle Touren einer Nachfrageschicht die gleiche als Verfahrensparameter „Mittlere Anzahl Aufträge pro Tour“ vorgegebene Anzahl Aufträge bedienen. Alle in einem Quellbezirk entstehenden Aufträge einer Nachfrageschicht (d.h. die Zeilensumme der zugeordneten Verteilungsmatrix) werden also gleichmäßig auf gedachte Touren verteilt. Daraus ergibt sich die Anzahl der in einem Quellbezirk k entstehenden Touren und somit auch der Startfahrten als
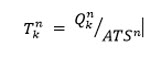
wobei
|
|
Anzahl Touren der Nachfrageschicht n mit Quellbezirk k |
|
|
Quellaufkommen der Nachfrageschicht n aus Quellbezirk k |
|
|
Mittlere Anzahl Aufträge pro Tour für Nachfrageschicht n |



Es kann vorausgesetzt werden, dass die mittlere Anzahl Aufträge pro Tour größer 1 ist, d.h. es gibt keine Leerfahrten.  ist somit kleiner oder gleich
ist somit kleiner oder gleich  , sodass in der Regel Aufträge verbleiben, die nicht bereits durch die Startfahrten bedient werden. Diese Aufträge werden im Rahmen von Verknüpfungsfahrten zwischen Bezirken bedient.
, sodass in der Regel Aufträge verbleiben, die nicht bereits durch die Startfahrten bedient werden. Diese Aufträge werden im Rahmen von Verknüpfungsfahrten zwischen Bezirken bedient.
Räumliche Verteilung der Startfahrten
Bei der räumlichen Verteilung der Startfahrten sind zwei Aspekte zu berücksichtigen. Zum einen folgt die räumliche Verteilung wie üblich einer durch Kenngrößen (Nutzenmatrix) und eine Bewertungsfunktion definierten nachfrageschicht-spezifischen Charakteristik. Weiterhin sind als Randbedingung jedoch die in der Erzeugung und Verteilung ermittelten Zielaufkommen je Bezirk als Obergrenze einzuhalten – es dürfen nicht mehr Startfahrten in einen Bezirk führen als dort Aufträge zu bedienen sind. Dazu wird eine bilineare Fassung des Multi-Verfahrens angewendet, ähnlich wie bei EVA-Verteilung und Moduswahl beschrieben. Bei einer weichen zielseitigen Randsummenbedingung bewirkt die Fixierung des Gesamtaufkommens
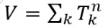 ,
,
dass auch die Summe der Zielaufkommen fixiert wird. Durch dieses Verfahren werden die Startfahrten proportional zum Zielaufkommen sowie zum transformierten Nutzen auf die Zielbezirke verteilt, unter Einhaltung der Zielaufkommen als Maximalwert in den Zielbezirken. Das Ergebnis wird in einer Matrix  festgehalten.
festgehalten.
Ermittlung der Restaufträge und der erforderlichen Verbindungsfahrten
Die Verbindungsfahrten werden jeweils separat pro Quellbezirk k betrachtet. In einem ersten Schritt wird ermittelt, welcher Teil der von k aus zu bedienenden Aufträge in den Zielbezirken nicht durch Startfahrten abgedeckt wird. Dazu werden die Startfahrten  von der Auftragsmatrix
von der Auftragsmatrix  abgezogen. Die so verbleibenden Restaufträge
abgezogen. Die so verbleibenden Restaufträge  müssen durch Verbindungsfahrten zwischen den Zielbezirken bedient werden.
müssen durch Verbindungsfahrten zwischen den Zielbezirken bedient werden.
Räumliche Verteilung der Verbindungsfahrten
In diesem Schritt werden die Fahrtbeziehungen ermittelt, mit denen die erforderlichen Verbindungsfahrten realisiert werden. Wie bereits bei der räumlichen Verteilung der Startfahrten sind wiederum mehrere Aspekte zu berücksichtigen. Das Maß, in dem die Verbindungsfahrten hinsichtlich der der Fahrtkosten optimiert werden, ist für die Nachfrageschichten unterschiedlich ausgeprägt. Stark optimierende Branchen, die in der Regel recht gleichartige, weitgehend homogen verteilte Aufträge bearbeiten (z.B. Paketdienste), realisieren tendenziell in hohem Maß mögliche Einsparungen. In anderen Bereichen, deren Auftragsbearbeitung stärker durch Faktoren wie feste Termine oder den Einsatz spezifischer Ressourcen und Mitarbeiter bestimmt ist (z.B. Dienstleister), spielt die Kostenoptimierung der Verteilfahrten eine geringere Rolle. Innerhalb der Branchen können wiederum unterschiedliche Optimierungsansätze für verschiedene Logistikstrukturen verfolgt werden. Die Ausgestaltung der Fahrtbeziehungen ist somit von Kostenmatrizen und einer Bewertungsfunktion abhängig und variiert zwischen den Nachfrageschichten.
Als Randbedingung der Ermittlung der Verbindungsfahrten müssen, wie schon bei der Verteilung der Startfahrten, auch hier die Zielaufkommen aus der Verteilungsmatrix der Aufträge eingehalten werden. Bei der Betrachtung der Kenngrößen (z.B. Fahrzeit) ist zu beachten, dass aufgrund der makroskopischen Perspektive keine Information über die Reihenfolge der durch Verbindungsfahrten bedienten Aufträge vorliegt. Statt expliziter Fahrtketten wird eine Verteilung der Verbindungsfahrten betrachtet. Daher ist es nicht sinnvoll, bei der Bewertung der Fahrtbeziehungen direkt auf die Kenngrößen (z.B. Reisezeit) zwischen den zu verknüpfenden Bezirken zurückzugreifen. Stattdessen wird ein Verfahren angewendet, das auf dem in der Tourenoptimierung verbreiteten SAVINGS-Algorithmus basiert. Die Betrachtung wird jeweils mit Bezug auf einen Quellbezirk k durchgeführt:
Für alle Paare von Bezirken i und j (inkl. k) werden die Einsparungen (Savings) ermittelt, die sich ergeben, wenn zwei separate Fahrten k- → i→ k + k→j→ k durch eine Rundtour mit Verbindungsfahrt k→ i→ j→ k ersetzt wird. Dafür muss das Restzielaufkommen  > 0 sein. Der Bezirk i könnte auch über eine Startfahrt erreicht worden sein, hier muss das Auftragsaufkommen
> 0 sein. Der Bezirk i könnte auch über eine Startfahrt erreicht worden sein, hier muss das Auftragsaufkommen  > 0 sein. Die für diese Berechnung zu verwendende Kostenmatrix
> 0 sein. Die für diese Berechnung zu verwendende Kostenmatrix  stimmt mit der Nutzenmatrix aus der Startfahrtenverteilung überein.
stimmt mit der Nutzenmatrix aus der Startfahrtenverteilung überein.
Das Maß, in dem die so ermittelten möglichen Einsparungen tatsächlich realisiert werden, ist wie oben beschrieben für die Nachfrageschichten unterschiedlich ausgeprägt. Es erfolgt daher eine Bewertung der realisierbaren Einsparungen mit nachfrageschicht-spezifischen Parametern. Beachten Sie, dass hier, anders als in der Startfahrtenverteilung, nicht Kosten bewertet werden, sondern Einsparungen. Während also für die Bewertung der Startfahrten ein monoton fallender Funktionsgraph verwendet wird, ist der Graph für die Bewertungsfunktion der Einsparungen steigend. Das heißt, wenn Sie beispielsweise Logitfunktionen verwenden, sollten Sie für den Parameter c ein entgegengesetztes Vorzeichen wählen. Sollten bei der Ermittlung der Einsparungen negative Werte auftreten, dann werden die transformierten Einsparungen auf Null abgebildet. Dies geschieht unabhängig von der verwendeten Bewertungsfunktion und sollte bei korrekter Parametrisierung nur vorkommen, wenn Touren von k nach i über j nach k teurer sind als die Summe aus den Touren k-i-k und k-j-k. In dem Fall werden die Rundtouren nicht verwendet.
Mit den bewerteten Kosteneinsparungen als Nutzenmatrix wird wieder ein bilineares Multi-Verfahren gerechnet (siehe oben). Die Restaufträge  müssen dabei als Spaltensumme, d.h. als harte zielseitige Randsummenbedingung, eingehalten werden. Für die Zeilensummen ist die Gesamtanzahl
müssen dabei als Spaltensumme, d.h. als harte zielseitige Randsummenbedingung, eingehalten werden. Für die Zeilensummen ist die Gesamtanzahl  der Aufträge eine obere Schranke, da maximal so viele Verbindungstouren hier starten können. Die
der Aufträge eine obere Schranke, da maximal so viele Verbindungstouren hier starten können. Die sind somit eine weiche quellseitige Randsummenbedingung. Das Ergebnis ist die Matrix
sind somit eine weiche quellseitige Randsummenbedingung. Das Ergebnis ist die Matrix  aller Verbindungsfahrten von Touren, die in Bezirk k beginnen.
aller Verbindungsfahrten von Touren, die in Bezirk k beginnen.
Bestimmung der Rückfahrten
Die Rückfahrten aus Bezirk i von Touren aus Bezirk k ergeben sich als Differenz aus der Anzahl aller Aufträge  nach i und den in i startenden Verbindungsfahrten:
nach i und den in i startenden Verbindungsfahrten:
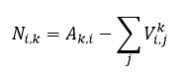
Ausgabe der Fahrtenmatrizen
Als Ergebnisse der Rechenschritte des Verfahrens entstehen jeweils eigene Matrizen der Startfahrten, Verbindungsfahrten und Rückfahrten je Nachfrageschicht. Diese werden zu einer Gesamtfahrtenmatrix je Nachfrageschicht zusammengefasst. Standardmäßig werden vom Verfahren nur die Gesamtfahrtenmatrizen gespeichert. Bei Bedarf können jedoch auch zusätzlich die Einzelmatrizen ausgegeben werden. Die Fahrtenmatrizen können in anschließenden Verfahrensschritten (Matrizen und Attributsvektoren während des Verfahrensablaufs kombinieren) gegebenenfalls noch zusammengefasst werden, z.B. anhand der in den Logistikstrukturen implizit referenzierten Verkehrssysteme oder Nachfragesegmente. Diese aggregierten Matrizen können dann in Umlegungsverfahren auf das Straßennetz umgelegt und z.B. hinsichtlich der Emissionen bewertet werden.
