|
Hinweis: Im HCM 2000 wird dieser Steuerungstyp in Kapitel 17 beschrieben, im HCM 2010 in Kapitel 20 und im HCM 6. Auflage im Kapitel 21. Die Berechnung im HCM 2010 erfolgt praktisch identisch zum HCM 2000. Im HCM 2010 wird eine Berechnungsvorschrift für Staulänge angegeben (HCM 2010, Seite 20-17), die im HCM 2000 fehlt. Außerdem erfolgt die Berechnung des Levels-of-Service unter Berücksichtigung der Auslastung. Bei Überlastung ist das Level-of-Service automatisch F. Die Berechnung im HCM 6. Auflage bzw. HCM 7. Auflage entspricht der Berechnung des HCM 2010. |
Die All-way stop controlled (AWSC)-Methode der Kapazitätsanalyse des HCM 2000 ist eine iterative Methode. Das Modell betrachtet alle möglichen Szenarios eines Fahrzeugs, das sich entweder auf einer Zufahrt oder nicht darauf befindet. Auf der Basis der eingegebenen Belastungen wird die Wahrscheinlichkeit des Eintretens eines jeden Szenarios sowie die mittlere Wartezeit berechnet. Die Auslastung v/c wird für jedes Szenario berechnet, das wiederum die anderen beeinflusst. Deshalb ist eine iterative Methode für die Bestimmung der Kapazität einer jeden Zufahrt erforderlich.
Anders als die signalisierte Methode, die auf der Basis von Signalgruppen arbeitet, oder die TWSC-Methode, die mit Fahrtbeziehungen arbeitet, verwendet das AWSC-Modell Fahrstreifen pro Zufahrt.
Die zugrunde liegende Berechnung wird im Ablaufdiagramm in Abbildung 77 dargestellt. Zusammen mit weiteren zusätzlichen Attributen wie PHF und %Lkw geben Sie die Knotenpunktgeometrie und die Belastungen ein. Die Belastungen werden angepasst und den Fahrstreifen zugeordnet. Der nächste Schritt ist dann die Berechnung der Anpassungsfaktoren für die Sättigungs-(Kapazitäts-)Fahrzeugfolgezeiten. Dann werden die Abfahrts-Fahrzeugfolgezeiten (das heißt die durchschnittliche Zeit zwischen zwei Abfahrten auf einem Fahrstreifen einer Zufahrt) auf der Basis aller Kombinationen von Wahrscheinlichkeiten berechnet. Diese Abfahrts-Fahrzeugfolgezeiten eines jeden Fahrstreifens einer jeden Zufahrt hängen von den anderen Zufahrten ab und werden daher iterativ berechnet. Ist ein konvergierter Wert gefunden, können Servicezeit, mittlere Wartezeit und LOS berechnet werden.
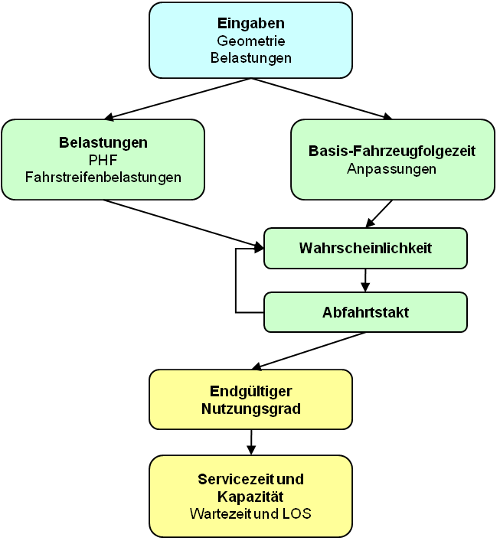
Abbildung 77: Ablauf der Berechnung bei einem All-Way-Stop-Knoten
Benutzen Sie das Operationsmodell HCM für All-way stop-Knoten, haben die in Tabelle 109 aufgeführten Visum-Attribute Auswirkungen. Überprüfen Sie, dass vor Beginn der Analyse realistische Werte eingestellt sind.
Die Ausgabe ist über die gleichen Attribute verfügbar wie bei signalisierten Knoten (Tabelle 100).
Der erste Schritt ist die PHF-Anpassung der Belastungen pro Fahrstreifen pro Fahrtbeziehung pro Zufahrt. Zusätzlich wird der Lkw-Anteil pro Fahrstreifen pro Fahrtbeziehung pro Zufahrt eingegeben, sofern verfügbar. Da in Visum Belastungen pro Fahrtbeziehung und nicht pro Fahrstreifen pro Fahrtbeziehung angegeben sind, werden diese gemäß einer Standardmethode zuerst auf die einzelnen Fahrstreifen disaggregiert.
Der nächste Schritt besteht in der Berechnung der Anpassungsfaktoren der Fahrzeugfolgezeit für jeden einzelnen Fahrstreifen. Die Berechnung erfolgt folgendermaßen:
hadj = hLTadj • pLT + hRTadj • pRT + hHVadj • pHV
wobei
|
hadj |
Anpassung Fahrzeugfolgezeit |
|
hLTadj |
Anpassung Fahrzeugfolgezeit Linksabbieger |
|
hRTadj |
Anpassung Fahrzeugfolgezeit Rechtsabbieger |
|
hHVadj |
Anpassung Fahrzeugfolgezeit Lkw |
|
pLT |
Anteil Linksabbieger in Zufahrt |
|
pRT |
Anteil Rechtsabbieger in Zufahrt |
|
pHV |
Anteil Lkw in Zufahrt |
Die Anpassungsfaktoren sind in Tabelle 110 aufgelistet.
|
Anzahl Fahrstreifen der betrachteten Zufahrt |
Anpassungsfaktor |
Sättigung |
Fahrzeugfolgezeit |
|
|
LT |
RT |
HV |
|
1 |
0,2 |
-0,6 |
1,7 |
|
2+ |
0,5 |
-0,7 |
1,7 |
Nach der Berechnung des Anpassungsfaktors Fahrzeugfolgezeit wird die Abfahrts-Fahrzeugfolgezeit iterativ berechnet. Die Berechnung erfolgt in fünf Schritten.
Schritt 1: Wahrscheinlichkeit kombinierter Wahrscheinlichkeiten berechnen
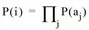
wobei
|
P(i) |
Wahrscheinlichkeit für Kombination i |
|
P(aj) |
Wahrscheinlichkeit des Konfliktgrades (degree-of-conflicts, DOC) für Kombination i des Fahrstreifentyps j |
|
aj |
1 oder 0 abhängig von Fahrstreifentyp j (siehe Tabelle 111) |
Diese Berechnung der Wahrscheinlichkeiten setzt sich aus mehreren Teilen zusammen. Für jeden Fahrstreifentyp j wird die P(aj) bestimmt. P(aj) wird auf der Grundlage einer Nachschlagetabelle berechnet (Tabelle 111).
|
aj |
Vj (Belastung konfligierende Zufahrt) |
P(aj) |
|
1 |
0 |
0 |
|
0 |
0 |
1 |
|
1 |
>0 |
Xj |
|
0 |
>0 |
1 - Xj |
|
Hinweise:
|
Der Wert aj ist der DOC-Tabelle entnommen (Tabelle 112). Diese Tabelle enthält alle Kombinationen von 0 bis 1 pro Fahrstreifen für jede Zufahrt. Für 2 Fahrstreifen pro Zufahrt sieht dies wie in Tabelle 112 dargestellt aus (siehe Anlage 17-30 in HCM 2000 für die ganze Tabelle).
Die Wahrscheinlichkeit für kombinierte Wahrscheinlichkeiten P(i) wird dann für jede Reihe (i) und für jede Spalte (Fahrstreifentyp) (j) berechnet. Zur Berechnung von P(i) nehmen wir das Produkt aller Wahrscheinlichkeiten der Fahrstreifen der Gegenrichtung und der konfligierenden Fahrstreifen P(aj). Das Ergebnis P(i) =∏P(aj) ist die Wahrscheinlichkeit für Reihe (i).
Schritt 2: Anpassungsfaktoren für Wahrscheinlichkeiten berechnen
Nach der Berechnung von P(i) für jeden Fall (i) muss eine Anpassung für jeden DOC-Fall berechnet werden. Die Anpassung berücksichtigt eine Reihenkorrelation in der vorherigen Berechnung aufgrund damit verbundener Konfliktfälle. Die Anpassungsgleichungen bei DOC-Fall (Ck) sind folgende:
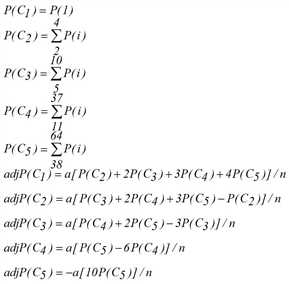
wobei
|
a |
0,01 (oder 0,00, falls keine Reihenkorrelation) |
|
n |
Anzahl der Nicht-Null-Fälle (i) für jeden DOC-Fall (höchstens n = 1 für C1, 3 für C2, 6 für C3, 27 für C4 und C5) |
Schritt 3: Angepasste Wahrscheinlichkeit berechnen
P‘(i) = P(i) + adjP(i)
wobei
|
P‘(i) |
Angepasste Wahrscheinlichkeit für Fall i |
|
P(i) |
Wahrscheinlichkeit des DOC für Fall i |
|
adjP(i) |
Anpassungsfaktor Wahrscheinlichkeit Fall i |
Schritt 4: Sättigungs-Fahrzeugfolgezeit berechnen
hsi = hadj + hbase
wobei
|
hsi |
Sättigungs-Fahrzeugfolgezeit pro DOC-Fall i |
|
hadj |
Anpassung Fahrzeugfolgezeit je Fahrstreifen |
|
hbase |
Basis-Fahrzeugfolgezeit je DOC-Fall i |
Die Basis-Fahrzeugfolgezeit hbase für jeden DOC-Fall i ist einer Nachschlagetabelle entnommen, die auf dem jeweiligen DOC-Fall (1–5) und der Geometriegruppe basiert (Tabelle 113).
|
Anzahl Fahrstreifen |
||||
|
Betrachtete Zufahrt |
Zufahrt Gegenrichtung |
Nicht verträgliche Zufahrt |
Knotenpunkttyp |
Geometriegruppe |
|
1 |
1 |
1 |
4-armig oder T |
1 |
|
1 |
1 |
2 |
4-armig oder T |
2 |
|
1 |
2 |
1 |
4-armig oder T |
3a / 4a |
|
1 |
2 |
2 |
T |
3b |
|
1 |
2 |
2 |
4-armig |
4b |
|
2 |
1 - 2 |
1 - 2 |
4-armig oder T |
5 |
|
3 |
1* |
1* |
4-armig oder T |
5 |
|
3 |
3 |
3 |
4-armig oder T |
6 |
|
Hinweis: * Verfügt die betrachtete Zufahrt über 3 Fahrstreifen und die Zufahrt der Gegenrichtung oder eine konfligierende Zufahrt über 1 Fahrstreifen, dann gilt Geometriegruppe 5, sonst Geometriegruppe 6. |
Das Modell wird für 3+ Fahrstreifen verallgemeinert, um es auf mehr als 4-armige Knotenpunkte anzuwenden. Die Erweiterung besteht darin, dass diese mehr als 4-armigen Fälle in Geometriegruppe 6 fallen.
Die Tabelle 114 zeigt die Grundwerte für die Sättigungs-Fahrzeugfolgezeit.
Der DOC-Fall hängt von den 64 Typen eines 4-armigen Knotenpunktes ab. Knoten mit mehr als vier Armen werden zunächst wie oben auf 4 Arme reduziert.
Schritt 5: Abfahrts-Fahrzeugfolgezeit berechnen
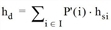
wobei
|
hd |
Abfahrts-Fahrzeugfolgezeit für Fahrstreifen |
|
hsi |
Sättigungs-Fahrzeugfolgezeit für jedes i in I |
|
P‘(i) |
angepasste Wahrscheinlichkeit für jedes i in I |
|
I |
Reihe der Tabelle 109 |
Diese fünf Schritte werden so lange wiederholt, bis die Werte der Abfahrts-Fahrzeugfolgezeiten konvergieren (Unterschied < 0.1). Die berechnete Abfahrts-Fahrzeugfolgezeit hd unterscheidet sich nun vom Ausgangswert. Daher wird die nächste Iteration ein anderes Ergebnis hervorbringen.
Nachdem nun die Abfahrts-Fahrzeugfolgezeit für jeden Fahrstreifen berechnet ist, können Servicezeit und Kapazität berechnet werden. Die Servicezeit wird wie folgt berechnet.
t = hd - m
wobei
|
t |
Servicezeit |
|
hd |
Abfahrts-Fahrzeugfolgezeit |
|
m |
Aufrückzeit (2,0 s bei Geometriegruppe 1-4, 2,3 s bei Gruppe 5-6) |
Für die Berechnung der Kapazität wird die Belastung auf dem betrachteten Fahrstreifen erhöht, bis der Nutzungsgrad (vjhd) / 3 600 auf dem betrachteten Fahrstreifen ≥ 1,0 ist. Die Belastung auf den anderen Zufahrten wird konstant gehalten. An diesem Punkt wird der Wert der Belastung der betrachteten Strecke als ihre Kapazität übernommen. Die Kapazität ist daher abhängig von den eingegebenen Belastungen einer jeden Zufahrt.
In einer linearen Implementierung geht die Suche nach der Kapazität langsam von statten. Daher wird einer binäre Suche mit einer oberen Grenze von 1 800 vphpl durchgeführt.
Die mittlere Wartezeit der Steuerung pro Fahrstreifen wird mittels unten stehender Gleichung berechnet. Die gewichtete mittlere Wartezeit einer Zufahrt wird auf der Grundlage der Gewichtungen der Fahrstreifenbelastungen, die mittlere Wartezeit am Knotenpunkt wird auf der Grundlage des gewichteten Mittels pro Zufahrtsbelastungen berechnet. Die Gleichungen sind dieselben wie diejenigen für signalisierte Knotenpunkte.
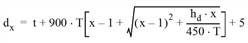
wobei
|
dx |
mittlere Steuerungswartezeit pro Fahrzeug für Fahrstreifen x |
|
t |
Servicezeit |
|
T |
Dauer des Analysezeitraums (h) (Standardwert 0.25 für 15 Min.) |
|
x |
Nutzungsgrad |
|
hd |
Abfahrts-Fahrzeugfolgezeit |
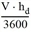
Der Level of Service kann anhand der Wartezeit am Knotenpunkt nachgeschlagen werden (Tabelle 115).
|
LOS |
Mittlere Wartezeit/Fahrzeug |
|
A |
0 – 10 s |
|
B |
10 – 15 s |
|
C |
15 – 25 s |
|
D |
25 – 35 s |
|
E |
35 – 50 s |
|
F |
50 + s |
Die vorgeschlagene Erweiterung auf 4+ Arme erfolgt durch die Zusammenfassung mehrfacher Links- oder Rechtsabbieger zu einem Links- oder Rechtsabbieger durch das Aufsummieren der Anzahl der Fahrstreifen bei der Berechnung konfligierender Verkehrsströme. Gibt es zum Beispiel 2 konfligierende Linksabbieger für eine betrachtete Zufahrt, eine mit einem Fahrstreifen und eine mit zwei Fahrstreifen, so werden diese zu einem konfligierenden Linksabbieger mit drei Fahrstreifen zusammengefasst. So kann der vorhandene Rahmen verwendet werden. Wahrscheinlich wird die Wartezeit etwas zu niedrig angegeben, aber im vorhandenen Rahmen wird es funktionieren und zu zusätzlicher Wartezeit für weitere Arme führen.
