Lors du calcul VISEM, vous pouvez enregistrer des matrices de sortie pour différents niveaux d’agrégation. Les matrices de la demande résultantes résultent de combinaisons possibles de groupe d’usagers, mode, activité d’origine, activité de destination et intervalle de temps.
Distribution des déplacements : chaînes de chemins par distribution en fonction des activités
VISEM assigne des zones de destination aux chemins en fonction de l’activité de destination de chaque chemin. Le choix d’une zone de destination dépend de différents facteurs.
- De la matrice d’utilité qui représente l’éloignement et le temps de la zone d’origine en fonction du trafic
L’utilité est dans ce cas inversement proportionnelle aux valeurs d’impédance telles que les temps de parcours ou les distances, et on a : plus le temps de déplacement ou la distance vers une zone de destination est élevé, plus son utilité est faible.
Il est également possible d’inclure la fonction LogSum des utilités spécifiques aux modes dans la matrice d’utilité. Ainsi, des indicateurs spécifiques tels que le temps de déplacement TI ou le nombre de ruptures TC sont inclus dans l’utilité totale dans les proportions du mode respectif.
- Du potentiel de destination des zones concurrentes pour la destination du chemin
- De l’influence de l’utilité, définie pour chaque groupe et chaque activité de destination dans les paramètres de la fonction d’utilité
Ces paramètres peuvent être estimés auparavant (Estimation des paramètres gravitaires (KALIBRI))
Ainsi, une multitude de chaînes de chemins sont générées à partir de chaque chaîne d’activités. Le résultat de la distribution des déplacements est non seulement la matrice du trafic total mais aussi l’ensemble de toutes les chaînes de chemins.
Pour le modèle de distribution, VISEM requiert un potentiel de destination Aj pour chaque activité, indiquant l’attractivité de chaque zone de manière quantitative. Ce potentiel de destination correspond pour chaque zone j à la valeur de la caractéristique de zone (Modèle de données VISEM) correspondant à l’activité.
La fonction d’utilité f(u ij) occupe une place centrale dans le modèle de distribution. Elle indique avec quelle probabilité Pij une des zones j est sélectionnée en tant que zone de destination de la zone d’origine i parmi toutes les possibilités de destination.
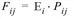
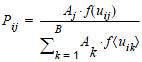
avec
|
Fij |
Nombre de chemins de la zone i vers la zone j |
|
Ei |
Volume émis dans la zone i |
|
Pij |
Probabilité du choix de la destination j pour la zone d’origine i |
|
Aj |
Potentiel de destination dans la zone j |
|
k |
Indice des zones (avec k= 1 pour le numéro de zone le moins élevé et Z pour le nombre de zones) |
uij décrivant l’utilité de la relation ij et la fonction d’utilité f(uij), par exemple de type Logit, pouvant être définie en tant que 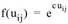 . Vous pouvez également utiliser tous les autres types de fonctions d’évaluation disponibles pour la procédure EVA en tant que fonctions d’utilité pour VISEM (Distribution des déplacements et choix modal EVA).
. Vous pouvez également utiliser tous les autres types de fonctions d’évaluation disponibles pour la procédure EVA en tant que fonctions d’utilité pour VISEM (Distribution des déplacements et choix modal EVA).
Dans ce cas, le choix du paramètre c pour chaque activité est décisif pour la distribution. c exprime l’influence de l’utilité sur les destinations de l’activité respective. Lorsque c = 0, l’utilité uij n’influe pas sur le choix de la destination. Plus c croît, plus l’influence de l’utilité uij influe sur le choix de la destination (Calculer le modèle gravitaire).
Vous spécifiez des paramètres de fonction distincts pour chaque combinaison de groupe d’usagers et activité de destination.
Afin d’illustrer les trois éléments centraux de la distribution, soit le potentiel de destination, la fonction d’utilité et la matrice d’utilité, nous poursuivons avec l’exemple de la génération des déplacements (Exemple pour la génération des déplacements VISEM).
Exemple pour la distribution des déplacements
On utilise une fonction d’utilité de type Logit pour les différentes transitions d’activités, donc 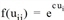 , avec le paramètre c = 0,4.
, avec le paramètre c = 0,4.
Les 93,4 chemins de la paire d’activités DT doivent mener de l’origine (zone 1) à des zones de destination potentielles comportant des emplois. VISEM distribue ces 93,4 chemins sur les zones de destination conformément au modèle de distribution décrit précédemment.
Pour plus de commodité, nous admettons que la zone 2 est la seule zone comportant des emplois, donc une zone avec un potentiel de destination positif pour l’activité Travail. Exprimé en nombres, cela donne par exemple Z1 = 0, Z2 = 100, Z3 = 0. Selon les formules de la distribution VISEM, on obtient P11 = 0, P12 = 1 et P13 = 0, et par conséquent F11 = 0, F12 = 93,4 et F13 = 0. La zone 2 est donc la destination de tous les chemins en provenance de la zone 1.
|
Nota : La définition de la fonction d’utilité n’influe pas sur le calcul dans ce cas. |
Après l’activité Travail, la probabilité du choix de destination pour les achats est calculée pour les chemins suivants TA à partir de la zone 2. On admet que les potentiels de destination sont définis comme suit pour l’activité Achats : Z1 = 0, Z2 = 50, Z3 = 50. On admet que l’utilité définie à partir de temps de parcours et de distances pour la transition TA de la relation 2-2 est deux fois plus élevée que celle de la relation 2-3, donc par exemple u22 = 2 et u23 = 1. Selon les formules de la distribution VISEM, on obtient à présent P21 = 0, P22≈ 0,6 et P23≈ 0,4, et par conséquent F21 = 0, F22≈ 56,0 et F23≈ 37,4. 40 % des chemins mènent donc à la zone 3 et 60 % à la zone 2 (c.-à-d. le trafic interne).
Dans le système, les probabilités des destinations pour le travail et pour les achats sont multipliées.
Pour la dernière paire d’activités de la chaîne, soit AD, aucune distribution n’est nécessaire, car dans la mesure où la zone 1 est la zone de domicile et l’origine du premier chemin de la chaîne, elle est également la destination du dernier chemin de la chaîne.
Il en résulte les matrices de transition suivantes.
- Matrice F1 pour la première transition d’activités (activité de destination T)
|
Zone |
93,4 |
1 |
2 |
3 |
|
93,4 |
Total |
0 |
93,4 |
0 |
|
1 |
93,4 |
0 |
93,4 |
0 |
|
2 |
0 |
0 |
0 |
0 |
|
3 |
0 |
0 |
0 |
0 |
- Matrice F2 pour la deuxième transition d’activités (activité de destination A)
|
Zone |
93,4 |
1 |
2 |
3 |
|
93,4 |
Total |
0 |
56,0 |
37,4 |
|
1 |
0 |
0 |
0 |
0 |
|
2 |
93,4 |
0 |
56,0 |
37,4 |
|
3 |
0 |
0 |
0 |
0 |
- Matrice F3 pour la troisième transition d’activités (activité de destination D)
|
Zone |
93,4 |
1 |
2 |
3 |
|
93,4 |
Total |
93,4 |
0 |
0 |
|
1 |
0 |
0 |
0 |
0 |
|
2 |
56,0 |
56,0 |
0 |
0 |
|
3 |
37,4 |
37,4 |
0 |
0 |
La totalisation aboutit à la matrice de la demande totale FT suivante.
|
Zone |
280,2 |
1 |
2 |
3 |
|
280,2 |
Total |
93,4 |
149,4 |
37,4 |
|
1 |
93,4 |
0 |
93,4 |
0 |
|
2 |
149,4 |
56,0 |
56,0 |
37,4 |
|
3 |
37,4 |
37,4 |
0 |
0 |
Récapitulatif de cet exemple de distribution
- DT : 100 % quittent la zone 1 avec pour destination la zone 2
- TA : 60 % restent dans la zone 2 et 40 % quittent la zone 2 pour rejoindre la zone 3
- AD : 100 % retournent dans la zone 1
Les chaînes de chemins qui en résultent sont les suivantes :
- 1-2-2-1 : 93,4 • 100 % • 60 % • 100 % = 56,0
- 1-2-3-1 : 93,4 • 100 % • 40 % • 100 % = 37,4
Les chaînes de chemins suivantes ont été générées :
- 56,0 chaînes de chemins 1-2-2-1
- 37,4 chaînes de chemins 1-2-3-1
|
Nota : Nous recommandons de tenir compte des aspects relatifs au comportement suivants lors de la définition des paramètres d’utilité :
|
VISEM permet de charger des matrices d’utilité spécifiques pour chaque activité. Des combinaisons de distances et de temps de parcours peuvent être la grandeur de base de matrices d’utilité.
|
Nota : La valeur absolue d’un potentiel de destination est dans un premier temps insignifiante, car elle est seulement incluse de manière relative au total des potentiels de destination de toutes les zones dans le modèle de distribution. Ainsi, le potentiel de destination Emplois = 1 000 dans une zone ne signifie pas nécessairement que VISEM mène 1 000 chemins avec l’activité de destination Travail dans cette zone. Le trafic attiré dépend plutôt du produit du potentiel de destination et de la valeur de la fonction d’utilité par rapport aux autres zones. |
Si la valeur absolue du potentiel de destination d’une activité est toutefois déterminante, comme cela peut être le cas avec le nombre d’emplois, elle peut être incluse dans le calcul au moyen de l’option Contrainte selon l’attrac. de la manière suivante. S’il existe par exemple 6 000 emplois dans le périmètre d’étude entier, la zone avec 1 000 emplois comporte alors un potentiel de destination relatif de 1 000/6 000 = 1/6 pour l’activité Travail. Si une couche de la demande présente un volume de domicile total de 3 000, le potentiel de destination absolu de la zone normalisé au volume de domicile total est de 3 000 • 1/6 = 500 pour cette couche de la demande. Cette valeur absolue est utilisée en tant que total marginal pour la destination dans le modèle gravitaire à contrainte double pour cette couche de la demande (Calculer le modèle gravitaire).
En règle générale, cette répartition prédéfinie du potentiel de destination pour les différentes couches de la demande ne reflète pas la réalité. Il s’agit bien plus d’épuiser conjointement le potentiel de destination de toutes les couches de la demande avec une contrainte selon l’attraction. Quand le calcul est effectué sur toutes les couches de la demande, la répartition du potentiel de destination sur les couches de la demande devient un résultat du calcul. On admet une répartition prédéfinie lorsqu’on étudie les couches de la demande individuelles.
Les résultats de la distribution des déplacements sont enregistrés de manière agrégée dans une matrice de la demande totale par groupe d’usagers et également pour différentes combinaisons d’intervalle de temps, mode, activité d’origine ou de destination.
Choix modal : modèle de répartition discrète
Le modèle de la demande VISEM présente un concept reposant sur le comportement des usagers qui reproduit les aspects suivants des situations de choix des usagers :
- la position socio-économique et la disponibilité des modes pour l’usager décisif (par différenciation en groupes d’usagers)
- différents attributs de tous les modes (par le modèle d’utilité)
- restriction de la liberté de choix dans les chaînes de chemins (par définition de modes interchangeables et non interchangeables)
Ce problème de choix est modélisé dans un modèle de répartition discrète qui indique la probabilité du choix d’un mode dans chaque chaîne de chemins existante.
Pour cela, les utilités subjectives doivent être calculées en fonction des indicateurs de mode (Temps de parcours, temps de rabattement et d’accès à destination, tarif, etc.). Vous pouvez définir des utilités différentes par activité de destination au besoin.
Ce modèle présente la forme fonctionnelle suivante.
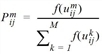
avec
|
i, j |
Indices des zones |
|
m |
Indice des modes (M = nombre total) |
|
Pmij |
Probabilité du choix du mode m lors du déplacement de i vers j |
|
umij |
Utilité en cas de choix du mode m pour le déplacement de i vers j |
La fonction d’utilité  peut p. ex. être du type Logit, et donc être définie par
peut p. ex. être du type Logit, et donc être définie par  . Vous pouvez également utiliser tous les types de fonctions d’évaluation disponibles pour la procédure EVA en tant que fonctions d’utilité pour le choix modal VISEM (Distribution des déplacements et choix modal EVA).
. Vous pouvez également utiliser tous les types de fonctions d’évaluation disponibles pour la procédure EVA en tant que fonctions d’utilité pour le choix modal VISEM (Distribution des déplacements et choix modal EVA).
Des combinaisons quelconques de distances et d’indicateurs spécifiques aux modes tels que les temps de parcours, de rabattement et d’accès à destination et les tarifs peuvent être utilisées en tant que grandeur de base pour les matrices d’utilité.
Le modèle Logit hiérarchisé constitue une forme particulière en raison du choix modal hiérarchisé opéré selon l’approche Logit. Un arbre de décision est défini à cet effet pour représenter la structure hiérarchique du modèle. L’arbre de décision peut se présenter p. ex. comme suit :
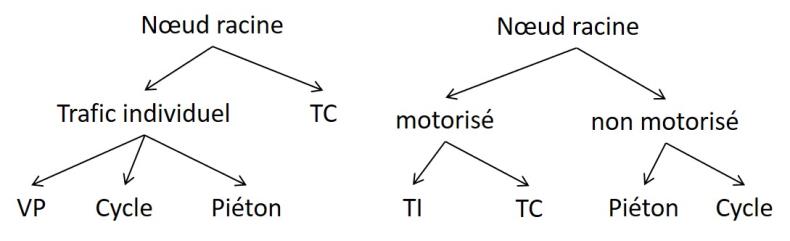
Des nœuds de nid (comme « Trafic individuel », « motorisé » ou « non motorisé ») ou des nœuds de mode (comme « VP », « Cycle », « Piéton », etc.) peuvent être définis sous le nœud racine. Au moins un nœud de mode doit être présent pour chaque mode du modèle de la demande. Le degré d’emboîtement est illimité quand chaque mode n’apparaît qu’une seule fois dans l’arbre de décision. Quand un mode apparaît à plusieurs reprises dans l’arbre de décision, le degré d’emboîtement est limité à deux niveaux sous le nœud racine et calculé selon le modèle Cross-Nested Logit.
Les probabilités de choix d’un mode sont calculées comme suit pour le modèle Logit hiérarchisé :
Supposons qu’il existe un nœud N avec un ensemble de nœuds enfants (nœuds de mode ou nœuds de nid) N1,…,NJ. L’utilité de chaque nœud Nj est désignée par UNj, le paramètre de mise à l’échelle au nœud N est μN. La probabilité de choix du nœud enfant Nj est la suivante :
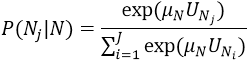
L’utilité provenant de la définition d’utilité du nœud est désignée par VN.
- Si N correspond à un nœud de mode du plus bas niveau, alors UN=VN.
- En cas contraire, N1,...,Nj sont les nœuds enfants du nœud de nid N. Le paramètre de mise à l’échelle de N est μN. L’utilité UN d’un nœud N est calculé comme suit :
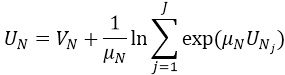 le terme de droite est désigné comme Fonction logsum
le terme de droite est désigné comme Fonction logsum
La probabilité de choix d’un nœud de mode résulte du produit des probabilités sur les niveaux hiérarchiques de la branche respective. Le nœud parent d’un nœud N est désigné par parent(N). N est un nœud de mode. Pour un k∈N, soit parentk(N) le nœud racine de l’arbre de décision. La probabilité de sélectionner le nœud de mode N résulte alors de :
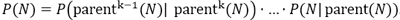
Quand un mode est défini à plusieurs reprises dans l’arbre de décision, le calcul est effectué d’après le modèle Cross-Nested Logit (Abbe, Bierlaire, Toledo, 2007, p. 795-808).
Nous supposons qu’il existe un ensemble de nœuds de nid C1,…,CM sous le nœud racine, et qu’il existe un ensemble de nœuds de mode N1m,…,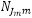 dans chaque nœud Cm. Un paramètre d’allocation αjm≥0 est assigné à chaque nœud de mode Njm. Le paramètre de mise à l’échelle est désigné par μ au nœud racine, et par μm à un nœud de nid Cm. Soient enfin Vjm et Vm les utilités provenant de la définition d’utilité des nœud de mode Njm et nœud de nid Cm.
dans chaque nœud Cm. Un paramètre d’allocation αjm≥0 est assigné à chaque nœud de mode Njm. Le paramètre de mise à l’échelle est désigné par μ au nœud racine, et par μm à un nœud de nid Cm. Soient enfin Vjm et Vm les utilités provenant de la définition d’utilité des nœud de mode Njm et nœud de nid Cm.
La probabilité du choix d’un nœud de mode Nim, en supposant qu’un nœud de nid Cm a été sélectionné, résulte de la formule :
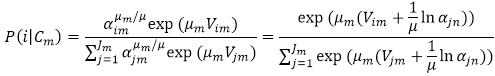 .
.
Si l’utilité est nulle au nœud de nid Cm, donc Vm=0, la probabilité de choix d’un nœud de nid Cm est :
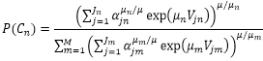
Et ainsi
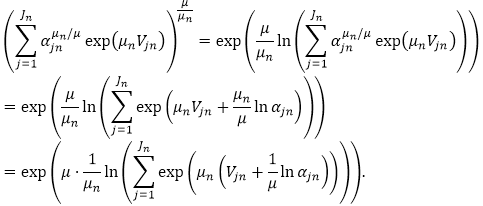
Expliquons pour conclure la signification du concept de chaînes de chemins dans le choix modal.
Dans Visum, les modes sont répartis de la manière suivante :
- modes interchangeables (en général marche, passagers, TC)
- modes non interchangeables (VP, cycle)
VISEM calcule un modèle de répartition discrète (par exemple Logit) pour le premier chemin de chaque chaîne de chemins (pour un groupe d’usagers) et choisit un mode. S’il s’agit d’un mode non interchangeable, il est conservé pour la chaîne de chemins entière, indépendamment des attributs de ce mode sur les chemins suivants. Si le mode choisi pour le premier chemin est interchangeable, un choix modal est calculé pour le reste des chemins de la chaîne mais uniquement parmi les modes interchangeables.
Exemple pour le choix modal
Nous poursuivons l’exemple de la distribution des déplacements (Exemple pour la distribution des déplacements) et déterminons les matrices pour les différentes transitions d’activités pour les trois modes VP (V), TC (X) et Marche (M). Seul le mode V n’est pas interchangeable. L’ensemble des modes interchangeables X et M est aussi désigné brièvement par I. On utilise à nouveau une fonction d’utilité de type Logit pour les différentes transitions d’activités, donc
 , avec le paramètre c = 0,4. Les matrices d’utilité um pour chaque mode m sont données par
, avec le paramètre c = 0,4. Les matrices d’utilité um pour chaque mode m sont données par
- uV
|
Zone |
1 |
2 |
3 |
|
1 |
3 |
3 |
3 |
|
2 |
3 |
3 |
3 |
|
3 |
3 |
3 |
3 |
- uX
|
Zone |
1 |
2 |
3 |
|
1 |
2 |
1 |
1 |
|
2 |
1 |
2 |
2 |
|
3 |
1 |
2 |
2 |
- uM
|
Zone |
1 |
2 |
3 |
|
1 |
1 |
1 |
1 |
|
2 |
1 |
1 |
1 |
|
3 |
1 |
1 |
1 |
Après évaluation de la formule ci-dessus, on obtient les matrices de probabilité suivantes.
- PV
|
Zone |
1 |
2 |
3 |
|
1 |
0,472 |
0,526 |
0,526 |
|
2 |
0,526 |
0,472 |
0,472 |
|
3 |
0,526 |
0,472 |
0,472 |
- PX
|
Zone |
1 |
2 |
3 |
|
1 |
0,316 |
0,237 |
0,237 |
|
2 |
0,237 |
0,316 |
0,316 |
|
3 |
0,237 |
0,316 |
0,316 |
- PM
|
Zone |
1 |
2 |
3 |
|
1 |
0,212 |
0,237 |
0,237 |
|
2 |
0,237 |
0,212 |
0,212 |
|
3 |
0,237 |
0,212 |
0,212 |
- PI = PX + PM
|
Zone |
1 |
2 |
3 |
|
1 |
0,528 |
0,474 |
0,474 |
|
2 |
0,474 |
0,528 |
0,528 |
|
3 |
0,474 |
0,528 |
0,528 |
Les probabilités pour les modes X et M au sein des modes interchangeables présentent également de l’intérêt.
- PIX = PX / PI
|
Zone |
1 |
2 |
3 |
|
1 |
0,598 |
0,5 |
0,5 |
|
2 |
0,5 |
0,598 |
0,598 |
|
3 |
0,5 |
0,598 |
0,598 |
- PIM = PM / PI
|
Zone |
1 |
2 |
3 |
|
1 |
0,402 |
0,5 |
0,5 |
|
2 |
0,5 |
0,402 |
0,402 |
|
3 |
0,5 |
0,402 |
0,402 |
La matrice du mode non interchangeable VP est d’abord calculée pour toutes les transitions d’activités. La matrice pour la première transition d’activités est le produit de PV par la matrice de la demande totale F1 de la première transition.
- Matrice de la demande totale F1 pour la première transition d’activités (activité de destination T)
|
Zone |
93,4 |
1 |
2 |
3 |
|
93,4 |
Total |
0 |
93,4 |
0 |
|
1 |
93,4 |
0 |
93,4 |
0 |
|
2 |
0 |
0 |
0 |
0 |
|
3 |
0 |
0 |
0 |
0 |
- Matrice FV1 pour le mode V et la première transition d’activités (activité de destination T)
|
Zone |
49,12 |
1 |
2 |
3 |
|
49,12 |
Total |
0 |
49,12 |
0 |
|
1 |
49,12 |
0 |
49,12 |
0 |
|
2 |
0 |
0 |
0 |
0 |
|
3 |
0 |
0 |
0 |
0 |
Ces 49,12 déplacements sont répartis sur les zones 2 et 3 avec les probabilités de distribution (P22 = 0,6 ou P23 = 0,4) à la transition d’activités suivante.
- Matrice FV2 pour le mode V et la deuxième transition d’activités (activité de destination A)
|
Zone |
49,12 |
1 |
2 |
3 |
|
49,12 |
Total |
0 |
29,47 |
19,65 |
|
1 |
0 |
0 |
0 |
0 |
|
2 |
49,12 |
0 |
29,47 |
19,65 |
|
3 |
10 |
0 |
0 |
0 |
Enfin, ces déplacements doivent revenir dans la zone de domicile 1 à la dernière transition d’activités.
- Matrice FV3 pour le mode V et la troisième transition d’activités (activité de destination D)
|
Zone |
49,12 |
1 |
2 |
3 |
|
49,12 |
Total |
49,12 |
0 |
0 |
|
1 |
0 |
0 |
0 |
0 |
|
2 |
29,47 |
29,47 |
0 |
0 |
|
3 |
19,65 |
19,65 |
0 |
0 |
La totalisation aboutit à la matrice de la demande totale VP suivante FVT
|
Zone |
147,36 |
1 |
2 |
3 |
|
147,36 |
Total |
49,12 |
88,59 |
19,65 |
|
1 |
49,12 |
0 |
49,12 |
0 |
|
2 |
88,59 |
29,47 |
29,47 |
19,65 |
|
3 |
19,65 |
19,65 |
0 |
0 |
Pour déterminer les matrices de la demande totale pour les modes non interchangeables, cette matrice VP est soustraite de la matrice de la demande totale FT (de la distribution des déplacements).
- FT
|
Zone |
280,2 |
1 |
2 |
3 |
|
280,2 |
Total |
93,4 |
149,4 |
37,4 |
|
1 |
93,4 |
0 |
93,4 |
0 |
|
2 |
149,4 |
56,0 |
56,0 |
37,4 |
|
3 |
37,4 |
37,4 |
0 |
0 |
La différence correspond dans un premier temps à la matrice de la demande totale pour tous les modes interchangeables ensemble.
- FI
|
Zone |
132,84 |
1 |
2 |
3 |
|
132,84 |
Total |
44,28 |
70,81 |
17,75 |
|
1 |
44,28 |
0 |
44,28 |
0 |
|
2 |
70,81 |
26,53 |
26,53 |
17,75 |
|
3 |
17,75 |
17,75 |
0 |
0 |
Pour cette matrice, un choix modal est uniquement calculé pour les modes interchangeables TC et Marche pour obtenir les matrices de la demande totale pour les modes TC et Marche. La matrice est multipliée par les probabilités PIX et PIM à cet effet.
- Matrice de la demande totale TC FX
|
Zone |
70,75 |
1 |
2 |
3 |
|
70,75 |
Total |
22,14 |
38,00 |
10,61 |
|
1 |
22,14 |
0 |
22,14 |
0 |
|
2 |
39,74 |
13,27 |
15,86 |
10,61 |
|
3 |
8,87 |
8,87 |
0 |
0 |
- Matrice de la demande totale Marche FM
|
Zone |
62,09 |
1 |
2 |
3 |
|
62,09 |
Total |
22,14 |
32,81 |
7,14 |
|
1 |
22,14 |
0 |
22,14 |
0 |
|
2 |
31,07 |
13,26 |
10,67 |
7,14 |
|
3 |
8,88 |
8,88 |
0 |
0 |
Veuillez noter que la matrice de la demande totale VP présente des totaux de ligne et de colonne identiques pour chaque zone, tandis que ce n’est pas nécessairement le cas pour les matrices TC et Marche.
Les résultats du choix modal peuvent être enregistrés de manière agrégée dans une matrice de la demande par groupe de la demande et par mode. Il est également possible de restreindre l’intervalle de temps, l’activité d’origine ou de destination pour des sorties désagrégées supplémentaires.